5. 집합 커버(Set Cover) 문제
- 집합 커버 문제: n개의 원소를 가진 집합 U가 있고, U의 부분집합들을 원소로 하는 집합 F가 주어질 때, F의 원소들인 집합들 중에서 어떻게 선택하여 합하면 선택하는 집합의 수를 최소화하면서 U와 같게 되는가?
- 신도시 학교 배치 문제 (응용): 10개의 마을이 있을 때, 등교 거리가 15분 이내가 되도록 학교들의 위치를 선정할 때, 어느 마을에 학교를 신설해야 학교의 수가 최소가 되는가?
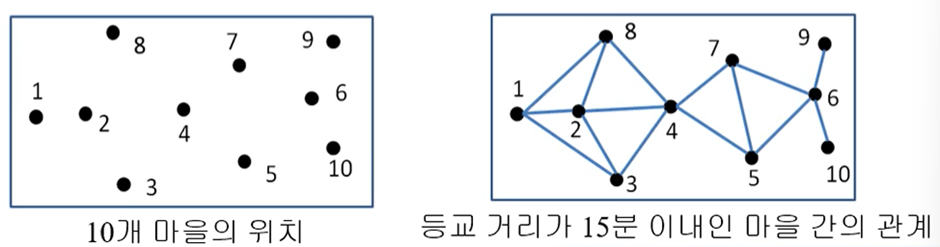



그렇다면 집합 커버 문제의 최적해는 어떻게 찾아야 할까?

n이 커질 때, 2n-1개를 다 검사하는 것이 비효율적이기 때문에 최적해가 아닌 근사해(approximation solution)를 찾는다




while 루프 수행 최대 n번 / Line 2 O(1) / Line 3 O(n2) / Line 4 O(n) / Line 5 O(1)
~ O(n)(루프 수행 횟수) * O(n2)(루프 1회) = O(n3)의 시간복잡도
* 도시 계획에서 공공 기관 배치, 경비 시스템 CCTV 배치, 컴퓨터 바이러스 찾기 등에 응용
6. 작업 스케줄링(Job Scheduling) 문제
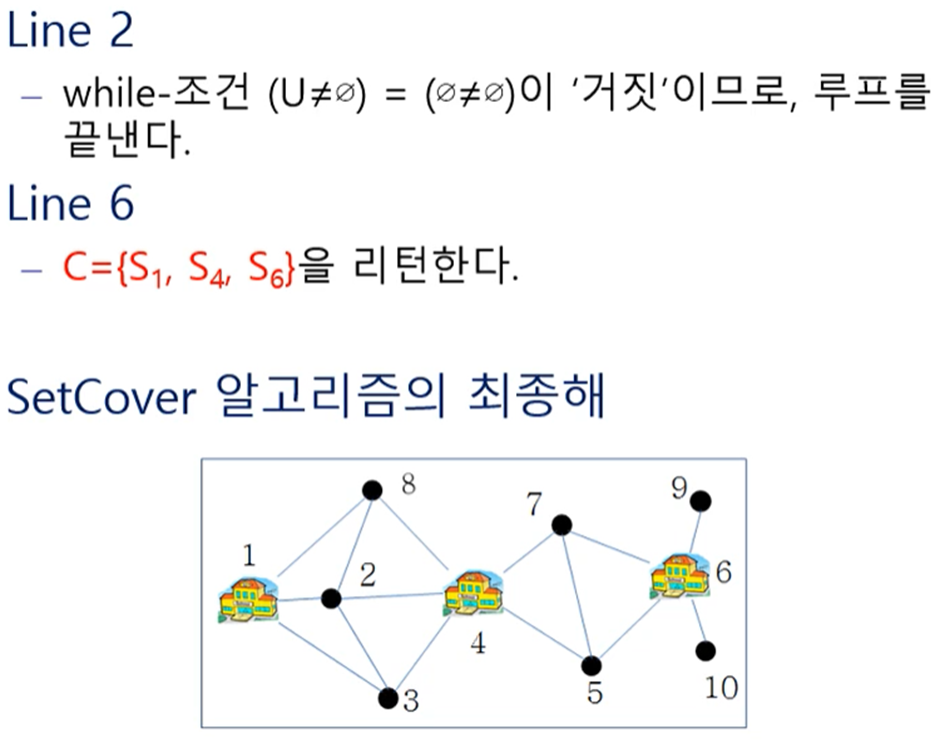
- 작업 스케줄링 문제: 작업의 수행 시간이 중복되지 않도록 모든 작업을 가장 적은 수의 기계에 배정하는 문제(= 학술대회에서 발표자들을 강의실에 배정하는 문제)
- 작업의 수: 입력의 크기로, 알고리즘 고안에 직접적으로 고려되는 요소가 아님
- 작업의 시작시간과 종료시간: 이를 통해 작업의 길이를 도출한다
다음 4가지 방식이 있는데, 빠른 시작시간 작업 우선 배정만 항상 최적해를 가진다
- 빠른 시작시간 작업 우선(Earliest start time first) 배정
- 빠른 종료시간 작업 우선(Earliest finish time first) 배정
- 짧은 작업 우선(Shortest job first) 배정
- 긴 작업 우선(Longest job first) 배정



n개의 작업 정렬 O(nlogn) / 작업 배정 O(m) * while 루프 n = O(mn)
~ O(nlogn) + O(nm)의 시간복잡도
* 비즈니스 프로세싱, 공장 생산 공정, 강의실 배정, 컴퓨터 테스크 스케줄링 등에 응용
7. 허프만(Huffman) 압축
- 파일의 각 문자가 아스키(ASCII) 코드로 저장될 때, 파일의 bit 수는 8 x (파일의 문자 수)이다. 이렇게 고정된 크기의 파일을 저장하거나 전송할 때, 파일을 크기를 압축하고 필요시 원래 파일로 변환하는 방식으로 전송 시간을 단축시킬 수 있는데, 파일의 크기를 줄이는 방법을 파일 압축(file compression)이라고 한다
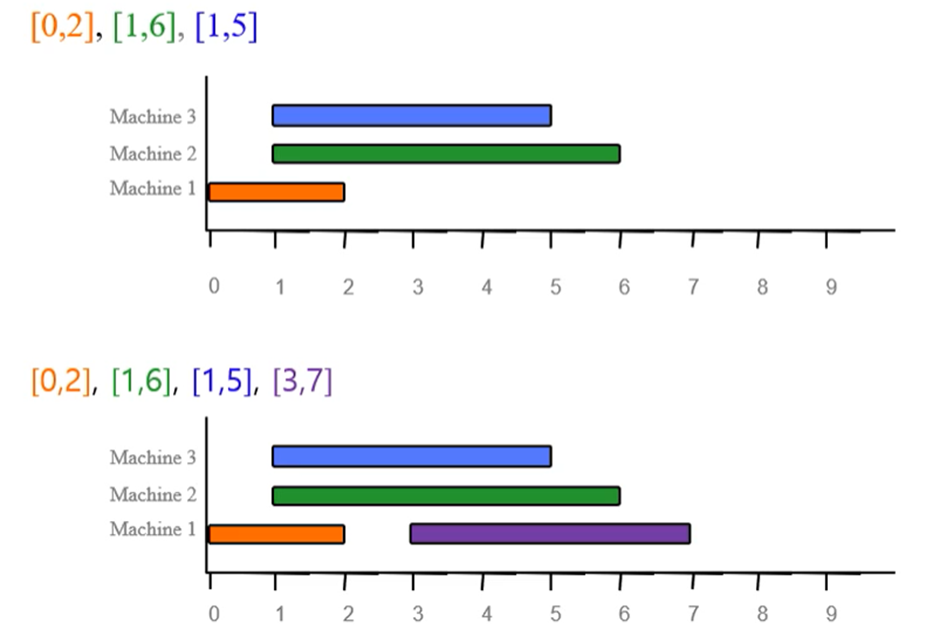
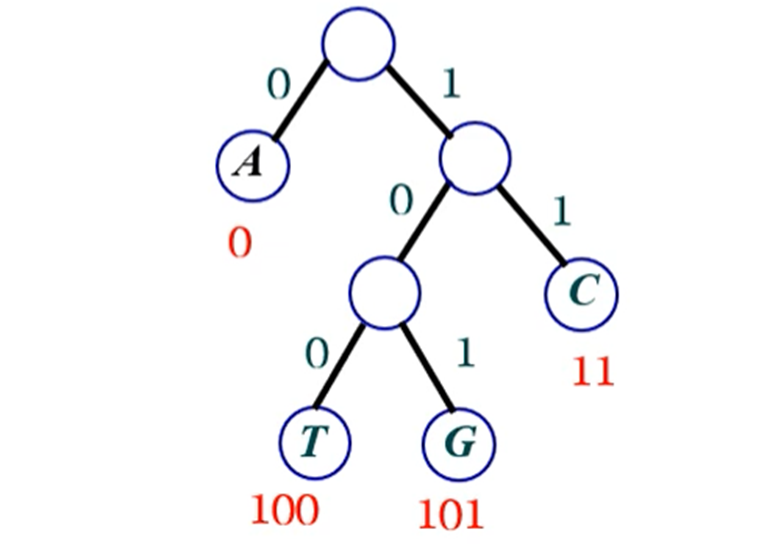
- 허프만 압축: 파일을 압축할 때, 파일에 빈번히 나타나는 문자에 짧은 이진 코드를 할당하고 드물게 나타나는 문자에 긴 이진 코드를 할당하는 방식
- 이 때 문자 코드들 사이에는 접두부 특성(prefix property)이 존재한다 (= 문자에 할당된 이진코드가 다른 문자에 할당된 이진 코드의 접두부(prefix)가 되지 않는다는 뜻으로, 문자 a에 할당된 코드가 101이라면 모든 다른 문자의 코드는 101로 시작되지 않으며 1이나 10도 아니다)
- 접두부 특성으로 인해 코드와 코드 사이를 구분할 특별한 코드가 필요하지 않고, 각 문자의 출현 빈도수를 기반으로 이진트리를 만들어, 각 문자에 이진 코드를 할당하는데 이를 허프만 코드라고 한다


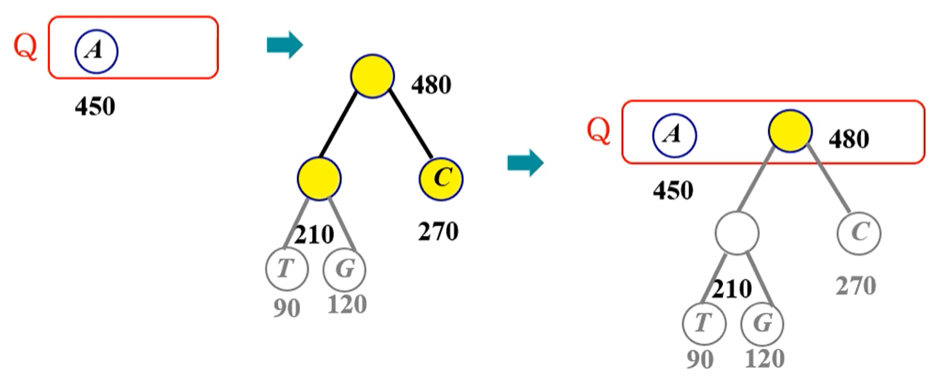
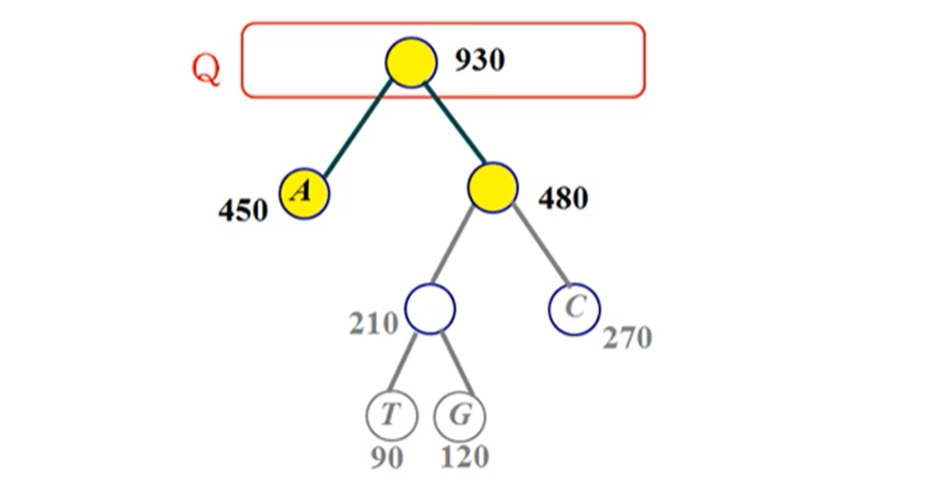

n개의 노드를 생성하고 빈도수를 노드에 저장 O(n) / n개의 노드로 힙(Heap)을 사용해 우선순위 Q 생성 O(n) / 최소 빈도수를 가진 노드 2개를 Q에서 제거하고 새 노드를 삽입 O(logn) x (n-1)(= while 루프 n-1번 반복) = O(nlogn) / 루트를 반환 O(1)
~ O(n) + O(n) + O(nlogn) + O(1) = O(nlogn)의 시간복잡도
* 팩스(FAX), 대용량 데이터 저장, MP3 압축, 정보 이론 분야 엔트로피(Entropy) 계산 등에 활용
'Computer Science > Algorithm' 카테고리의 다른 글
| [HUFS/알고리즘] #7 NP-완전 문제 (0) | 2022.05.02 |
|---|---|
| [HUFS/알고리즘] #6 정렬 알고리즘 (0) | 2022.04.18 |
| [HUFS/알고리즘] #4 그리디 알고리즘(1) (0) | 2022.04.04 |
| [HUFS/알고리즘] #3 분할 정복 알고리즘(2) (0) | 2022.03.28 |
| [HUFS/알고리즘] #2 분할 정복 알고리즘(1) (0) | 2022.03.21 |