B-트리

데이터가 입력되는 순서대로 쌓이는 순차 방법은 레코드들의 논리적 순서가 저장 순서와 동일
~ 물리적 순서대로 레코드에 접근하며 파일 복사, 순차적 일괄 처리에 응용

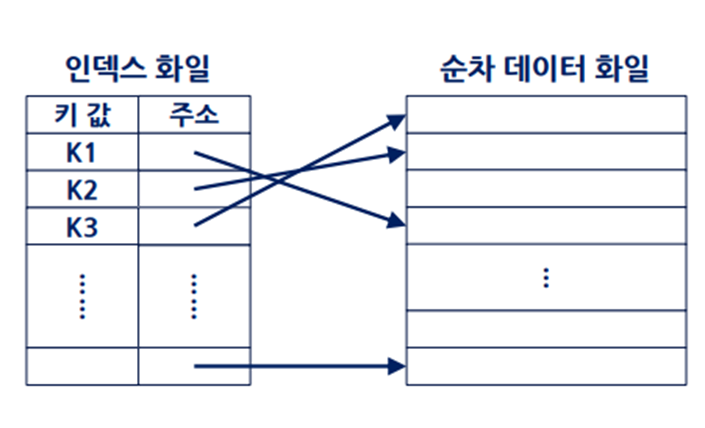
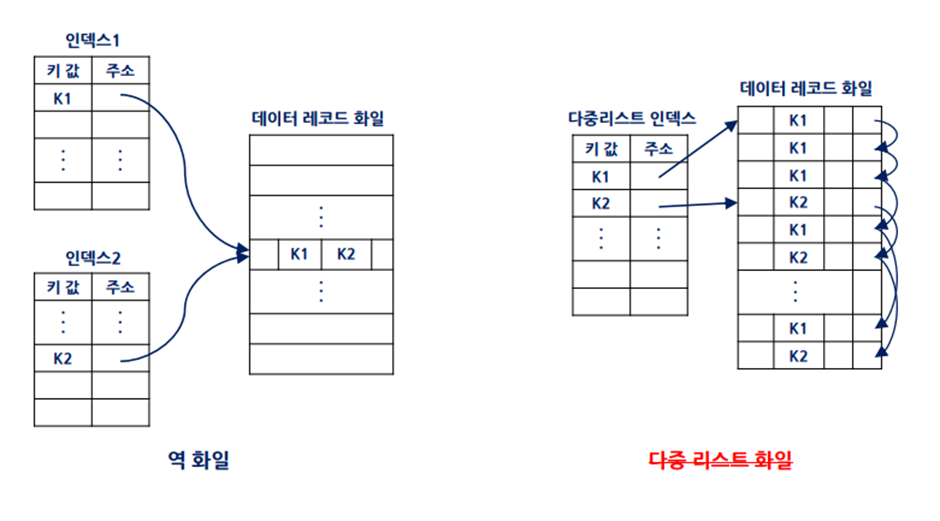
인덱스의 종류)
- 기본키에 대한 인덱스라면 기본 인덱스, 아니라면 보조 인데스
- 레코드가 키 값 순으로 정렬되었다면 집중 인덱스, 아니라면 비집중 인데스
- 모든 키에 대해서 인덱스 엔트리가 있다면 밀집 인덱스, 아니라면 희소 인데스
* 인덱스 엔트리: 레코드 키 값 + 포인터
디스크에 인덱스를 만들 때, 데이터를 저장하는 탐색 트리
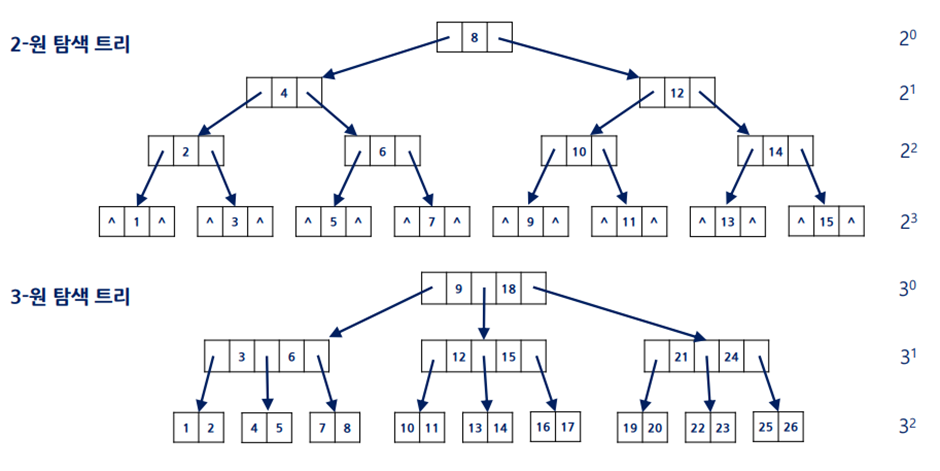

m-원 탐색 트리 중 모든 자식 노드가 균형을 유지하는 경우 B-트리라고 한다

B-트리의 조건)
- 공백이거나 높이가 1이상인 m-원 탐색 트리
- 루트와 리프를 제외한 내부 노트는 최소 m/2, 최대 m개의 서브트리를 가짐
- 루트는 그 자체가 리프가 아닌 이상 적어도 두 개의 서브트리를 가짐
- 모든 리프는 같은 레벨에 있음
B-트리는 검색/삽입/삭제/변경 연산을 할 때, 중위 순회하며 키 순서로 탐색하고
어떤 연산을 수행하더라도 결과적으로 균형을 유지해야 한다


B-트리는 순차접근시 과도한 디스크I/O가 발생하기 때문에
인덱스 세트와 순차 세트로 구성된 B+트리가 등장


해시 인덱스
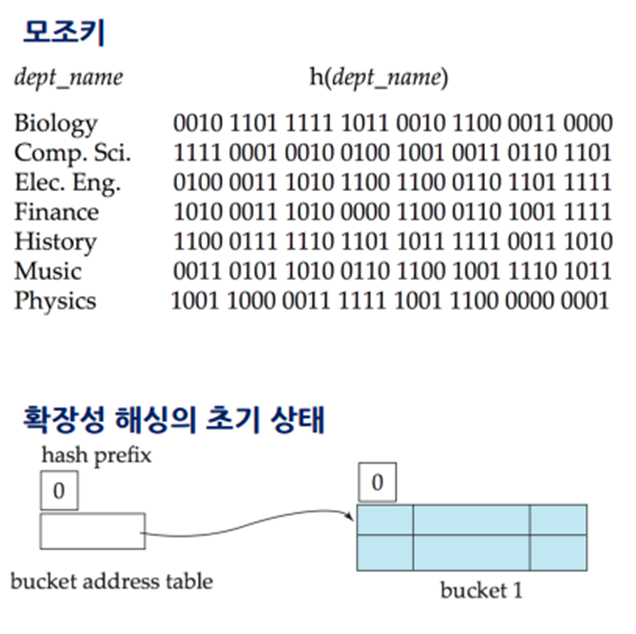
해싱(hashing): 다른 레코드의 참조 없이 계산에 의해 목표 레코드의 접근을 직접 하는 것
~ 키 값과 레코드 주소 사이의 사상 관계를 해싱 함수로 설정한다 (키 -> 주소) 삽입/검색
버킷 해싱은 데이터를 버킷에 저장하는 방식이다

서로 다른 키 값이 동일한 버킷 주소로 변환된다면 충돌(collision)이 일어나며,
이 때 오버플로 버킷이 생겨난다면 해싱의 장점을 잃기 때문에 확장성 해싱으로 충돌에 대처한다

비트맵 인덱스
애트리뷰트의 값이 몇가지 되지 않을 때(소득수준, 성별, 국가 등) 비트맵 인덱스를 활용한다
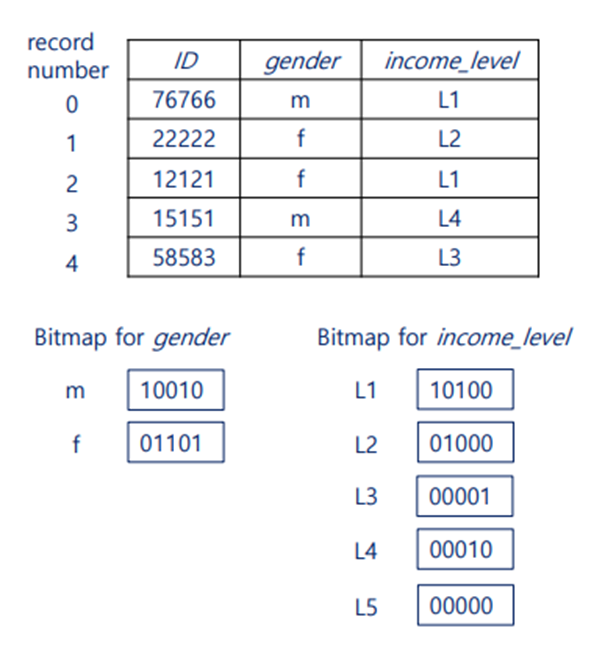

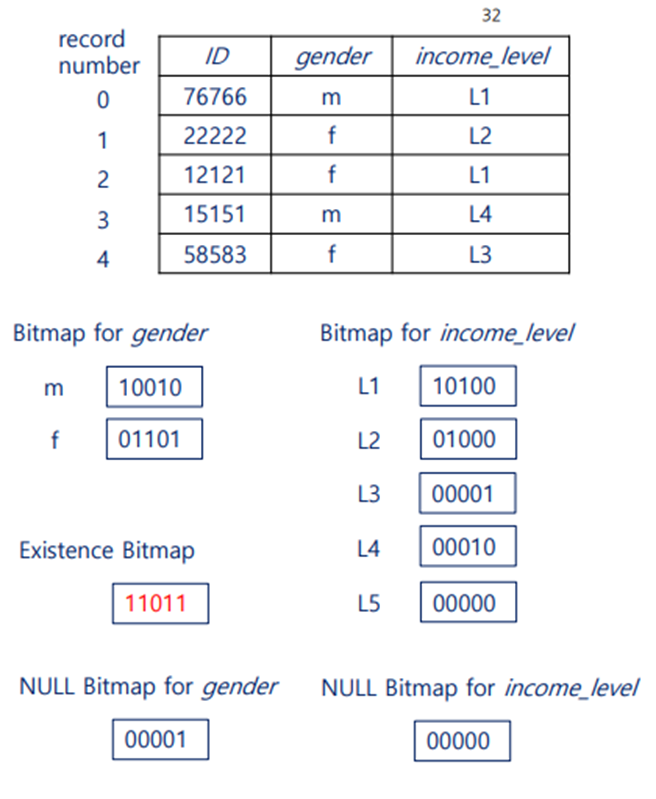
지금처럼 하나의 키를 사용하는 파일들과 달리 다중 키 파일은 R-Tree를 사용한다


'Computer Science > Database, SQL' 카테고리의 다른 글
| [HUFS/데이터베이스] #17 회복 (6) | 2021.12.12 |
|---|---|
| [HUFS/데이터베이스] #16 질의어 처리 (0) | 2021.12.05 |
| [HUFS/데이터베이스] #14 데이터베이스 설계 (0) | 2021.11.10 |
| [HUFS/데이터베이스] #13 데이터 모델링과 E-R 모델 (4) | 2021.11.03 |
| [HUFS/데이터베이스] #12 데이터 종속성과 정규화 (0) | 2021.11.03 |