정렬(sort)
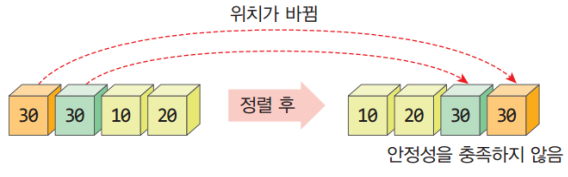
정렬이란 데이터를 순서대로 재배열하는 것으로 비교가 가능한 모든 속성들이 정렬의 기준이 될 수 있으며 오름차순(ascending order)/내림차순(descending order)이 있다
여러 개의 필드로 구성되는 레코드는 정렬의 대상이며 정렬 키를 기준으로 정렬된다

정렬 알고리즘은 1차적으로 내부 정렬(메인 메모리), 외부 정렬(+외부 기억 장치)로 나뉘며,
단순하지만 비효율적 방법: 삽입, 선택, 버블 정렬 등
복잡하지만 효율적 방법: 퀵, 힘, 병합, 기수 정렬, 팀 등으로 세분화된다
1. 선택 정렬(selection sort)



2. 삽입 정렬(insertion sort)



3. 버블 정렬


+++
3장의 집합 자료구조를 항상 정렬하도록 수정해보자


탐색과 맵 구조
탐색이란 테이블에서 (원하는 탐색키를 가진) 레코드를 찾는 작업이다
맵(map) 또는 딕셔너리(dictionary)는 엔트리/키를 가진 레코드의 집합이며
엔트리는 파이썬의 딕셔너리처럼 키(레코드 탐색키)와 값(탐색키 관련 값)으로 이루어진 구조이다

1. 순차 탐색
정렬 or 정렬되지 않은 배열의 처음부터 마지막까지 하나씩 검사하는 간단한 탐색 방법이다


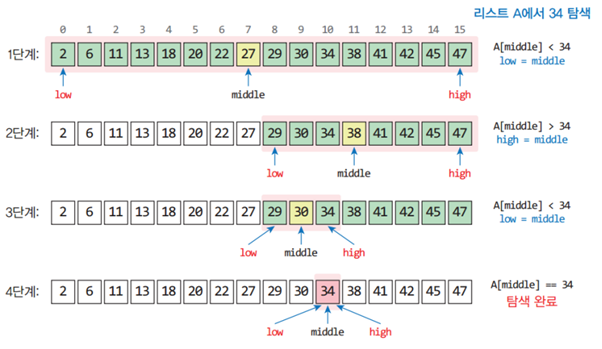
2. 이진 탐색
정렬된 배열에만 적합하며 먼저 배열의 중간 값을 조사해 더 큰지/작은지 비교한 후 오른쪽/왼쪽으로 다시 반으로 나눠 중간 값을 조사해 반복하는 탐색 방식으로 순차탐색보다 상당히 빠르다

3. 보간 탐색
탐색키가 존재할 위치를 예측하여 탐색하는 방법으로 리스트를 불균등하게 분할하여 탐색한다
탐색 값과 위치는 비례한다는 가정 하에 가중치 방식으로 연산하는 이진 탐색의 응용이다
해싱(hashing)
키 값에 대한 산술적 연산에 의해 테이블의 주소를 계산하는 방식으로,
해시 테이블을 통해 직접 접근이 가능한 구조이다

해시 함수가 탐색키를 입력 받아 해시 주소를 생성한다
서로 다른 키가 해시 함수에 의해 같은 주소로 계산되는 충돌이 발생할 수 있다

공간이 부족해서 충돌이 슬롯 수보다 많다면 오버플로우가 발생할 수 있다 (모든 자리에 충돌)





이 외에도 충돌 발생시 다른 해시 함수로 위치를 계산(재해싱)하는 이중 해싱법도 있다
하나의 버킷에 여러 레코드를 저장하는 체이닝으로 오버플로를 처리할 수 있다

성능을 좌우하는 좋은 해시 함수의 조건은 다음과 같다
- 충돌이 적어야 한다
- 함수 값이 테이블의 주소 영역 내에서 고르게 분포(군집화X)
- 계산이 빨라야 한다



'Computer Science > Algorithm' 카테고리의 다른 글
| [HUFS/자료구조] #9 탐색 트리 (0) | 2021.11.25 |
|---|---|
| [HUFS/자료구조] #8 트리 (0) | 2021.11.18 |
| [HUFS/자료구조] #6 연결 리스트 (0) | 2021.10.21 |
| [HUFS/자료구조] #5 큐와 덱 (2) | 2021.10.14 |
| [HUFS/자료구조] #4 스택 (0) | 2021.09.30 |