관계 데이터 모델 (relational data model)
계층형/네트워크형 DB와 달리 관계형 DB를 사용하면서 비절차적 질의가 가능해짐
관계형 데이터 모델은 집합(set)과 릴레이션(relation)에 기반을 두고 있다
사용자는 이를 테이블의 형태로 생각하는데,,
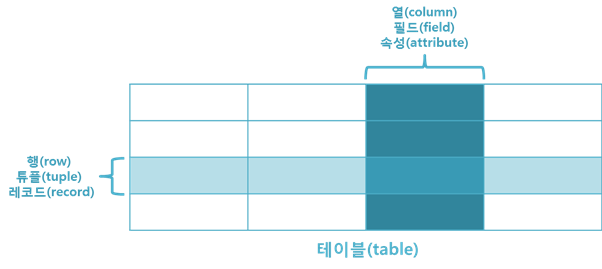

즉, 테이블과 달리 relation의 tuple은 중복이 허용되지 않으며 attribute의 순서에 의미가 없다
관계형 데이터 베이스는 모든 데이터를 이러한 relation의 형태로 저장한다
이 때, relation의 attribute가 취할 수 있는 값들의 집합을 도메인(domain)이라고 한다
* attribute와 domain의 이름이 같을 수도 있다
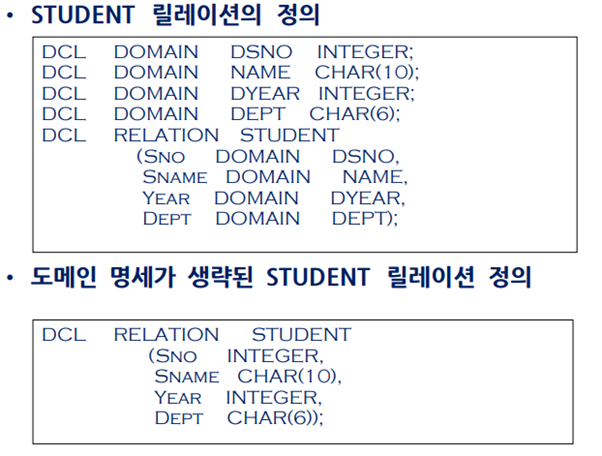

스키마(Schema)와 인스턴스(Instance)
이러한 개요를 Relation Schema(relation과 attribute의 이름)로 간단하게 표헌

* 물론 이렇게 표현된 스키마는 동적이지 않고 정적인 상태로 멈춰있다
이렇게 표현된 스키마에 맞게 tuple(= record)이 들어가는데,,
이러한 tuple들의 집합을 Relation Instance라고 한다

* 스키마와 달리 삽입, 삭제, 갱신되는 동적인 성질이 있다
결론적으로 Relation R은 도메인에 맞게 나올 수 있는 모든 인스턴스의 부분집합인 셈이다
Relation의 특성
앞서 언급했듯 relation의 tuple은 유일성(uniqueness)과 무순서성(no ordering)을 가지기 때문에
attribute들 간에도 마찬가지로 순서에 의미가 없으며 ~ 무순서성(no ordering)
이러한 attribute들은 논리적으로 더 이상 분해할 수 없는 원자성(atomicity)을 가진다
~ 정규화 과정을 통해 원자성을 가진 속성만 허용하기 때문이다
* Relation에서는 null도 아직 정해지지 않았다는 논리적인 하나의 값이다

'Computer Science > Database, SQL' 카테고리의 다른 글
| [HUFS/데이터베이스] #6 관계 대수 (0) | 2021.09.22 |
|---|---|
| [HUFS/데이터베이스] #5 무결성 제약 (4) | 2021.09.15 |
| [HUFS/데이터베이스] #3 데이터베이스 시스템의 구성 (0) | 2021.09.08 |
| [HUFS/데이터베이스] #2 데이터베이스 관리 시스템 (0) | 2021.09.08 |
| [HUFS/데이터베이스] #1 데이터베이스 환경 (6) | 2021.09.01 |